By an odd coincidence, I’ve played two games with “7” in the title recently, and both are sort of related to a larger project I have going on. So I want to talk about the games, and the project, and probably whatever else comes to mind while I’m typing this up.
That’s a polite way to say “Buckle up, I’m going to ramble incoherently for the next few pages.”

After Resident Evils 5 and 6, 7 (Should I say VII?) came as a real shock. No more mowing down hordes of zombies and zombie-related enemies as Professional Badasses Chris and/or Leon, you’re just a poor sap stuck in a crazy house full of cannibal hillbillies. And it’s freaky as all get out. So much so, in fact, that I moved OFF the big screen and onto my iPad where the smaller screen helped to considerably lessen the scare factor.
Oh, side note – big shout out to Capcom for including the iPad version when you buy the Mac version, and vice versa. With the exception of Resident Evil: Village, they did that for all of their recent Mac ports, and it’s appreciated.
Thankfully, the intensity drops a bit after about the first two hours of the game. I don’t think I could have played through the entire thing if it had stayed at the same level throughout.
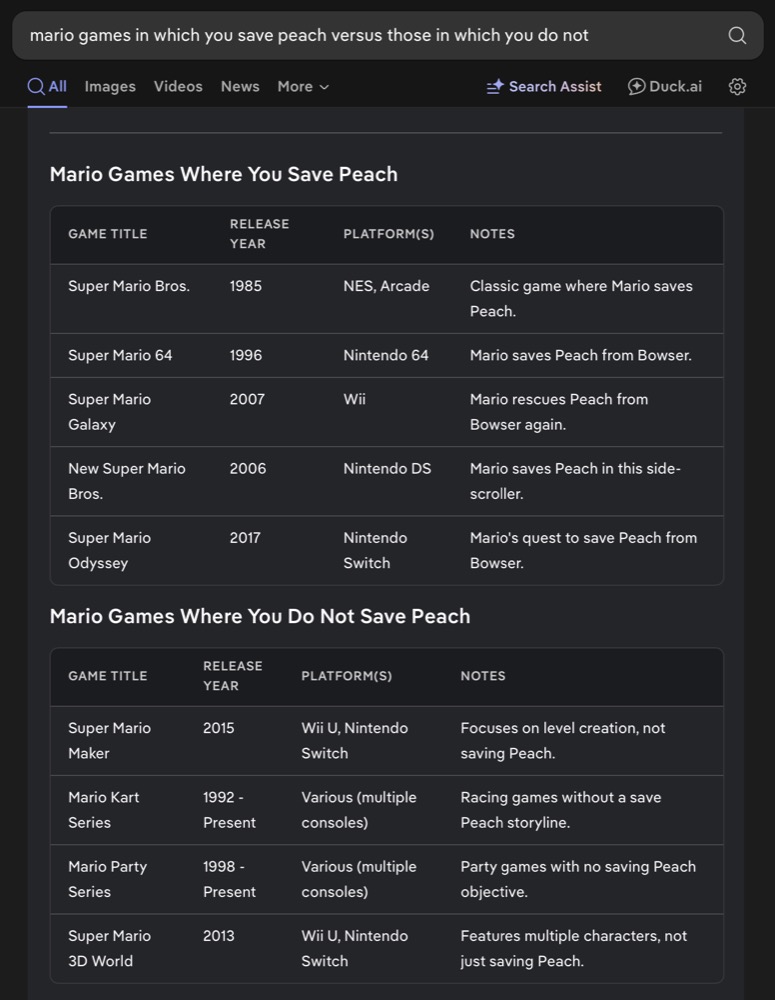
But I did beat it! Admittedly on easy.
And then I played through the “Daughters”, “Not a Hero” and “End of Zoe” DLC expansions because I wanted to get more of the story.
Two of those expansions are very much action games, which was pretty cathartic after the main game. They serve pretty well to give a backstory and proper ending for the game, as well, so I’d really consider them mandatory.
And yes, I did say “Mac” because this is one of those rare cases where a relatively modern AAA title is playable on something with an Apple logo. The last similarly-recent game I tried was Stray, back in 2023, and it wasn’t a great experience compared to the Windows version. RE7 looked and played great, both at 1080P and at 4K upscaled from 1080P, on my M2 Pro MacBook Pro.
Note: I wasn’t insane enough to try 1440P or 4K native. And it IS technically a PS4 game so “it looks great” on a laptop from 2023 isn’t that much of a testimony. But I was pretty happy with the performance.
The other “7” game I played was nothing BUT action, being the latest roller-coaster-ride-with-guns from Activision.

Of the various sub-series under the overall Call of Duty brand, I have really come to enjoy the Black Ops titles the most. While there have been some stumbles, like the year it completely omitted the campaign mode, they have a completely different feel from the ripped-from-the-headlines Modern Warfare games. They get to jump all over history and they can get very weird at times.
CODBLOPS7 leans HEAVILY into the weird. I would put it right up with El Shaddai in terms of never knowing what the next level was going to throw at me, and I would like to be very clear that I am paying it a compliment there. It starts off with an almost depressingly by-the-numbers sequence where you and your team of heavily-armed buddies (well, not a team really, I’ll get to that) raid some secret laboratory run by Evil Corporation Seeking To Dominate The World Or Something, and then you all get exposed to some sort of crazy virus and then roughly half the levels are just drug-induced hallucinations of the highest order.
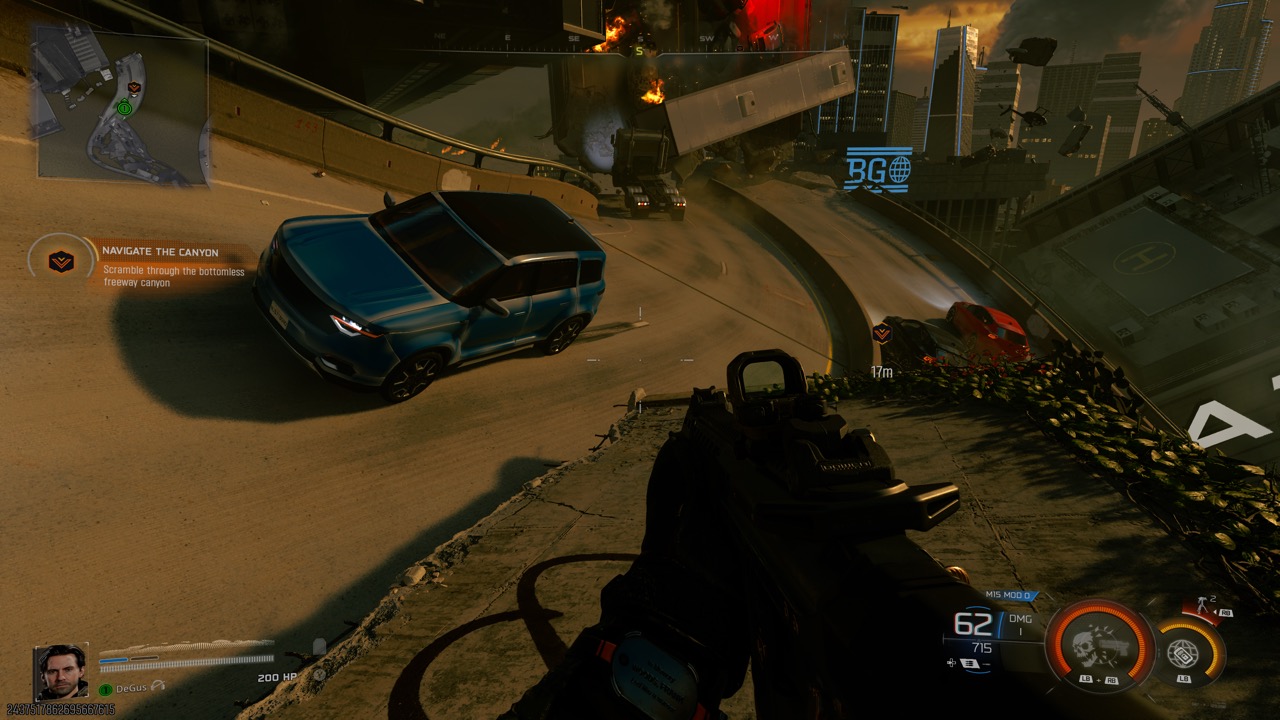
My favorite was a level that had you running down the LA freeways, only the the roads were twisted around and all seemed to have their own gravity so you would have cars on the “ceiling” and enemies shooting at you from the walls which were their floors. It was utterly bonkers and visually confusing in the best way.
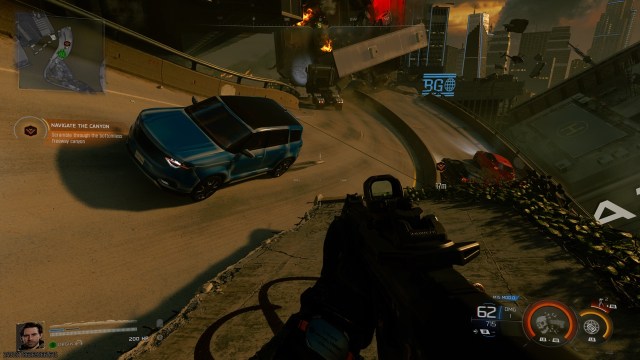
Even the levels that didn’t take place inside hallucinations looked GOOD. Another high point was the Japan level which was all neon and colorful billboards.

Sorry that screenshots from the game are kind of dark, Windows has yet to figure out how to get a decent capture from an HDR display.
I didn’t take many screenshots, because one thing I will say against it is that the attention to little details in the world seemed a little lacking compared to older titles. No cool 80s tech to get shots of this time.
There was, at least, one scooter.

The other thing that seemed just peak silliness was a hacking mini-game that you run into occasionally. Seriously, I did not expect a pipe game in the middle of my Call of Duty.

There was also one weird …puzzle? Where you are locked in a room trying to find a passcode to open a door. It stood out because every other door in the game is either locked until you kill everything trying to kill you or simply requires you to walk up to it and push the “open door” button. For some reason, in this ONE CASE, they really wanted you to look around this room for a four digit number.
It’s 5912, by the way, or at least it was for me. Maybe it’s random!
In short, I really enjoyed the campaign… eventually. It does not start well and it has a weird focus on trying to make you play it in co-op mode, to the point where if you DO dare to play it solo it is a weirdly solitary experience where you are supposed to have three other characters with you, and they talk to you as if they are with you, but you only see them in cutscenes. Hence the “not a team really” caveat from before. Also, if you don’t watch the intro movie – you know, the actual lead-in to the story? – there is NO WAY to watch it again and you cannot wipe your entire progress and start a new game. So when you start this campaign, sit down and watch it because otherwise you are going to be stuck looking it up on YouTube.
Also it needed a title card along the lines of “This story is a sequel to Black Ops II, which you played a decade ago, so maybe go back and look up a summary eh?” but that is a minor point.
I acknowledge that very few people play the Calls of Duty for the campaigns, so my perspective on the game is not particularly applicable to the average player. For reference, here are my achievements for beating the last four games. Note the percentage of players who have done the same.
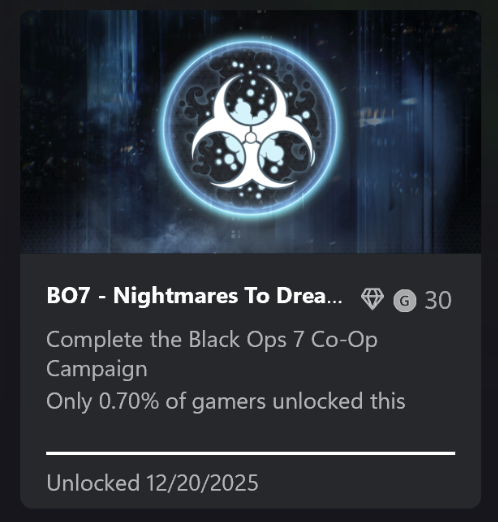
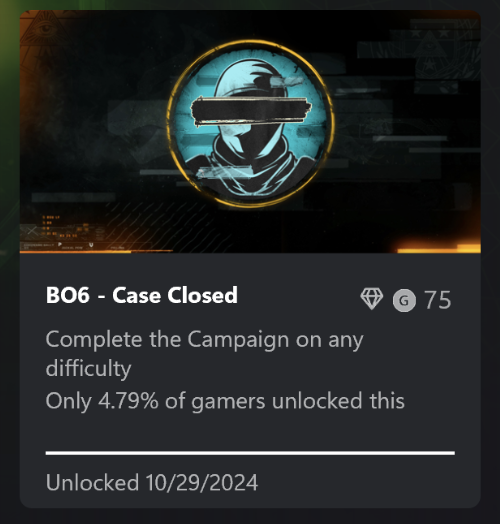

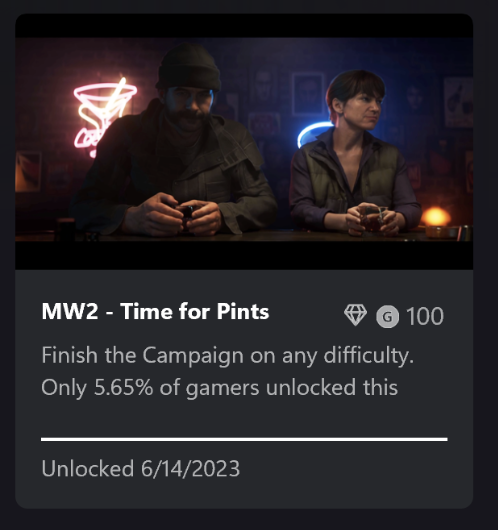
Yeah, it’s not very high. And it’s not like these are long games! I am told that if you play the BLOPS7 campaign in co-op mode, it’s like five hours long!
It took me considerably longer solo, but that’s expected. They really do not want you playing this without three random people from Xbox Live friends.
Anyway! I really wanted to get through this by the end of the year, because one of my goals for 2026 is to move completely away from Windows.
I already only keep Windows systems in the house for the purpose of playing games, but Linux has gotten considerably better in that regard and CrossOver, on the Mac, isn’t AS good as Proton but is still pretty decent.
Oh, right, that’s the big project I alluded to. Yup. After years of apologizing for Microsoft’s less-popular-quirks (I will STILL defend Windows Vista), I finally got broken by a Windows 11 prompt that kept popping up that had the choices of
- Yes
- “Ask me again in a week”
with no way to say “no, stop asking me and never ask me again”.
If I ever need to use Windows for work, or if Microsoft ever decides to drastically reverse course on their nonsense, maybe I’ll give it another try.
Neither CrossOver nor Proton can play games from Game Pass or from the Windows Store, however, so I needed to knock CoD out before the end of the year. I only have one more game in that category, which is a moderately-long RPG from Bandai-Namco called Scarlet Nexus. I should be able to get that off the backlog before the ball drops in Times Square.